numad 정의
- NUMA는 Non-Uniformed Memory Access(불균일 기억장치 접근)의 약자
- CPU 소켓이 하나가 있는 데스크탑이 아니고, 여러개의 CPU 소켓을 가지고 있는 서버에서 메모리에 효과적으로 접근하기 위해서 사용되는 기술
- 여러개의 CPU 소켓이있는 환경에서, 하나의 프로세서가 전체 메모리에 접근하게 될 경우 메모리 버스를 점유하게 되고 다른 프로세스들은 대기하여야 하는 상황이 발생
- 위와 같이 메모리 버스를 독점하는 문제를 해결하기 위해서, 각 CPU 마다 지역 전용적으로 사용하는 지역 메모리(Local Memory)으로 할당하고, 지역 메모리를 사용하는 CPU 코어들을 묶어서 하나의 NUMA 노드로 할당
- numad는 자동 NUMA 친화도 관리 데몬
- numad는 백그라운드 데몬과 같은 형태로 시스템에 상주
- 사전 배치 조언 서비스를 통해 여러 작업 관리 시스템 쿼리에 대해 적절한 CPU와 메모리 리소스의 초기 바인딩을 제공 가능
- numad는 /proc 파일 시스템에서 주기적으로 정보에 액세스하여 각 노드에서 사용 가능한 시스템 리소스를 모니터링
- 서버의 실제 하드웨어 사진 → 파랑색 : CPU, 빨강색 : CPU와 가까운 메모리 영역

numad의 장점
- 리눅스에서는 numad를 통해 NUMA 메모리 할당 정책을 직접 설정하지 않고도 메모리 지역성을 높일 수 있는 방법을 제공
- 시스템의 NUMA 토폴로지 및 리소스 사용량을 모니터링하여 동적으로 NUMA 리소스 할당 및 관리 (즉 시스템 성능)를 향상
- 시스템 작업량에 따라 numad는 성능 기준의 최대 50% 까지 성능을 개선 가능
- 일정 수준의 지정된 리소스 사용량을 유지하며 필요에 따라 NUMA 노드 간 프로세스를 이동하여 리소스 할당을 재조정
- numad는 시스템의 NUMA 노드의 하위 집합에서 중요한 프로세스를 배치 및 격리하여 최적의 NUMA 성능을 구현
- numad는 주로 상당한 리소스 양을 소비하고 전체 시스템 리소스의 하위 집합에 있는 프로세스에서 장기간 실행 중인 프로세스가 있는 시스템에 이점을 제공
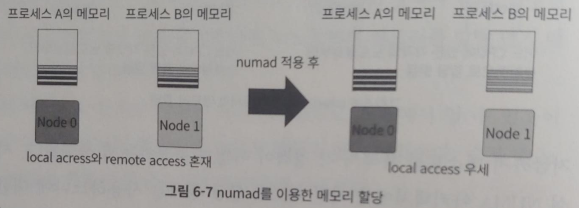
- 프로세스 A와 B 두개가 동작하고 있는 시스템 가정
- default 정책에 따라 메모리 지역성을 높인 상태로 운영 가능
- 각 프로세스가 필요로 하는 메모리가 여러 노드에 걸쳐서 존재하는 것 가능
- 프로세스가 필요로 하는 메모리가 노드 하나의 메모리 크기보다 메모리의 크기보다 작은 경우 노드 하나의 메모리 크기보다 작기 때문에 충분히 메모리 지역성을 높일 수 있음
- 다수의 프로세스를 관리해야 하는 경우 numactl 등을 사용해 수작업으로 실행하기 어려움
- numad → 하나의 프로세스가 필요로 하는 메모리를 하나의 노드에서만 할당 받을 수 있도록 설정할 수 있기에 메모리의 지역성을 높이고 성능을 최적화 가능
numad의 단점
- 여러 NUMA 노드의 리소스를 소비하는 애플리케이션에 유용하지만 시스템 리소스 소비율이 증가하면 numad에서 얻을 수 있는 효과는 감소
- 프로세스의 실행 시간이 몇 분이거나 많은 리소스를 소비하지 않는 경우 numad는 성능을 개선하지 않을 가능성이 높음
- 대형 메모리 데이터베이스와 같은 지속적으로 예상치 못한 메모리 액세스 패턴을 갖는 시스템도 numad의 사용으로 혜택을 얻을 가능성이 낮음
- numad가 대체적으로 좋은 성능을 낼 수 있도록 도와주지만 문제점이 발생할 수 있는 상황 존재
- 프로세스 A는 interleaved 정책으로 실행되어 각각의 노드에서 메모리를 순차적으로 할당
- 이때 프로세스 B가 실행되고, 프로세스 B는 메모리 요청이 노드 하나의 크기보다 작아서 numad에 의해 한쪽 노드에 바인딩되고 해당 노드로부터 메모리를 할당
- 문제는 프로세스 B가 지역성을 높이기 위해 Node 1에서 메모리 할당을 너무 많이 받아서 더 이상 프로세스 A에 할당해 줄 메모리가 없을 때 발생
- 프로세스 A는 워크로드에 따라 interleave로 실행되었지만 numad가 지역성을 너무 높인 탓에 메모리 불균형이 발생
- numad는 사용자가 신경 쓰지 않아도 메모리 할당 문제를 해결해 주긴 하지만 경우에 따라서는 오히려 성능에 좋지 않은 영향을 미칠 수 있음
- 현재 시스템의 워크로드에 따라 numad를 켜는 것이 더 좋을지 아닐지 판단이 필요

NUMA 아키텍처(NUMA Architecture)
1. NUMA
- Non-Uniform Memory Access의 약자 → 불균형 메모리 접근이라는 뜻
- 멀티 프로세서 환경에서 적용하는 메모리 접근 방식
- 로컬 메모리로의 접근이 동시에 이뤄질 수 있음
- 0번 CPU가 자신의 로컬 메모리에 접근하는 동안 1번 CPU도 자신의 메모리에 접근할 수 있어서 성능 향상
- 로컬 메모리의 양이 모자라면 다른 CPU에 붙어있는 메모리에 접근이 필요하게 되고, 이때 메모리 접근에 시간이 소요되어 예상치 못한 성능 저하를 경험하게 됨
- 로컬 메모리에서 얼마나 많이 메모리 접근이 일어나느냐가 성능 향상의 가장 중요한 포인트
- NUMA 아키텍처에서의 메모리 접근

2. UMA
- Uniform Memory Access의 약자 → 균형 메모리 접근이라는 뜻
- NUMA와 반대되는 개념으로 초창기 아키텍처
- 모든 프로세서가 공용 BUS를 이용해서 메모리에 접근
- UMA의 문제점은 BUS를 동시에 사용할 수 없는것
- 0번 소켓에 있는 CPU가 메모리에 접근하는 동안 1번 소켓에 있는 CPU는 메모리에 접근 X
- UMA 아키텍처에서의 메모리 접근

리눅스에서 NUMA 확인
- 리눅스에는 NUMA를 활용하기 위한 코드를 구현해 놓았고 명령어를 통해서 현재 시스템의 NUMA 상태를 확인
1. numactl 명령어
NUMA와 관련된 정책을 확인하거나 설정할 때 사용
--show 명령으로 NUMA 정책을 확인
# numactl 명령어가 없다면 패키지 install 필요 $ yum install numactl -y $ numactl --show # 기본 정책이 default # default는 현재 사용 중인 프로세스가 포함된 노드에서 메모리를 먼저 가져다가 사용하는 방식 policy: default preferred node: current physcpubind: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 cpubind: 0 1 nodebind: 0 1 membind: 0 1
- NUMA와 관련된 메모리 할당 정책
- default 정책
- 별도의 설정을 하지 않는 한 모든 프로세스에 적용
- 현재 실행되고 있는 프로세스가 포함된 노드에서 먼저 메모리를 할당 받아 사용
- bind 정책
- 특정 프로세스를 특정 노드에 바인딩시키는 방식
- 0번 노드에 할당하면 0번 노드에서만 메모리를 활용 가능
- 메모리의 지역성이 좋아지기 때문에 메모리 접근 속도가 빨라서 성능이 좋아짐
- bind에 설정한 노드의 메모리가 부족하면 성능이 급격히 나빠질 수 있음
- preferred 정책
- bind와 비슷하지만 선호하는 노드를 설정
- bind가 반드시 설정한 노드에서 메모리를 활용 → preferred는 가능한 한 설정한 노드로부터 메모리를 할당 받음
- interleaved 정책
- 다수의 노드에서 거의 동일한 비율로 메모리를 할당
- Round-Robin 정책에 따라 다수의 노드로부터 한 번씩 돌아가면서 메모리를 할당 받음
- default 정책
numactl -H 명령어 설명
available
- NUMA 노드가 2개로 구성되어 있음
node 숫자 cpus
- 각각의 노드 0, 1에 해당하는 CPU의 번호와 각 노드에 할당된 메모리의 크기
- CPU 번호는 시스템마다 조금씩 다를 수 있음
node distances
각 노드의 메모리에 접근하는 데 걸리는 시간
각각의 로컬 메모리에 접근할 때 소요되는 시간이 10
리모트 메모리, 즉 0번 노드에서 1번 노드에 있는 메모리에 접근하거나, 1번 노드에서 0번 노드에 있는 메모리에 접근할 때 소요되는 시간이 21
node distances는 절대적인 시간이 아니라 상대적인 값
리모트 메모리에 접근하는 시간이 로컬 메모리에 접근하는 데 필요한 시간의 2.1배
$ numactl -H # NUMA 노드가 2개로 구성 available: 2 nodes (0-1) # node 0의 속성 node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 node 0 size: 128192 MB node 0 free: 126040 MB # node 1의 속성 node 1 cpus: 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 node 1 size: 128993 MB node 1 free: 126084 MB # 각 노드의 메모리에 접근하는 데 걸리는 시간 node distances: node 0 1 0: 10 21 1: 21 10
2. numastat 명령어
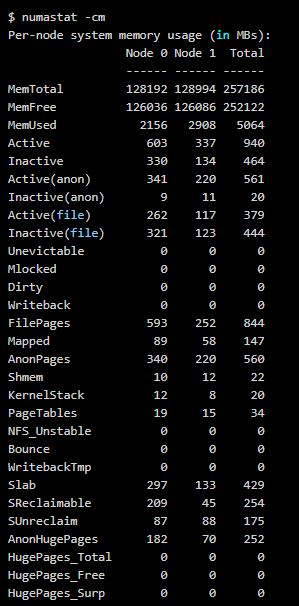
- NUMA 환경에서 현재 시스템에 할당된 메모리의 상태를 확인
- NUMA 아키텍처에서 메모리 불균형 상태를 확인
- 어느 한쪽 노드의 메모리 사용률이 높으면 메모리 할당 정책에 따라 swap을 사용하는 경우 발생
- 전체 메모리에는 free 영역이 많이 있는데도 불구하고 메모리 할당 정책에 따라 한쪽 노드에서 메모리 할당이 과하게 일어나면 swap이 사용 → numastat 명령어로 확인 가능
- numastat -cm 명령어 출력
3. 프로세스가 어떤 메모리 할당 정책으로 실행되었는지 확인
- /proc/
/numa_maps은 현재 동작 중인 프로세스의 메모리 할당 정책과 관련된 정보가 기록 $ cat 21631/numa_maps 55ca074c5000 default file=/usr/libexec/postfix/pickup mapped=47 N0=47 kernelpagesize_kB=4 55ca07706000 default file=/usr/libexec/postfix/pickup anon=2 dirty=2 N1=2 kernelpagesize_kB=4 55ca07708000 default file=/usr/libexec/postfix/pickup anon=1 dirty=1 N1=1 kernelpagesize_kB=4 55ca07709000 default anon=1 dirty=1 N1=1 kernelpagesize_kB=4 55ca080ae000 default heap anon=18 dirty=18 N1=18 kernelpagesize_kB=4 7fdae8bb5000 default file=/usr/lib64/libnss_sss.so.2 mapped=7 mapmax=10 N1=7 kernelpagesize_kB=4 7fdae8bbd000 default file=/usr/lib64/libnss_sss.so.2 7fdae8dbc000 default file=/usr/lib64/libnss_sss.so.2 anon=1 dirty=1 N1=1 kernelpagesize_kB=4 7fdae8dbd000 default file=/usr/lib64/libnss_sss.so.2 anon=1 dirty=1 N1=1 kernelpagesize_kB=4 7fdae8dbe000 default file=/usr/lib64/libnss_files-2.17.so mapped=9 mapmax=47 N1=9 kernelpagesize_kB=4 7fdae8dca000 default file=/usr/lib64/libnss_files-2.17.so 7fdae8fc9000 default file=/usr/lib64/libnss_files-2.17.so anon=1 dirty=1 N1=1 kernelpagesize_kB=4 7fdae8fca000 default file=/usr/lib64/libnss_files-2.17.so anon=1 dirty=1 N1=1 kernelpagesize_kB=4 7fdae8fcb000 default
※ 로컬 엑세스(Local Access)
- 각각의 CPU마다 별도의 메모리가 있는데 이와 같이 메모리에 접근하는 방식
※ 노드(Node)
- CPU와 메모리를 합쳐서 노드(Node)라고 함
※ 리모트 엑세스(Remote Access)
- NUMA에서는 자신의 메모리가 아닌 다른 노드에 있는 메모리에도 접근하는 방식
'OS(운영체제)' 카테고리의 다른 글
| 프로세스가 사용하는 메모리(VIRT, RES, SHR) 양 확인 (0) | 2022.06.29 |
|---|---|
| OOM Killer와 OOM Scoring (0) | 2022.06.29 |


