- Disk의 read/write 통계지표 및 CPU 사용률, queue 대기열 길이 등 io에 대한 지표를 실시간으로 볼 수 있는 유용한 tool
- iostat 지표로 부하(read/write) 주는 job의 블록 크기, 부하 크기, 레이턴시 등의 정보를 확인 가능
- Linux kernel에서 IO 발생 시 CPU와 device의 사용률 정보를 /proc/diskstats, 또는 /sys/block/[device]/stat에 저장
- kerenl에선 해당 diskstats 파일에 기록된 정보를 바탕으로 값들을 계산해서 iostat 지표에 출력
- iostat 필드 중 대표적으로 많이 보는 %util 필드의 경우 아래와 같이 계산하여 출력
- iostat는 Disk에 문제가 발생할 때 주로 보게 되는 툴이지만, Nvme나 SSD에서는 %utils가 의미 X
- %util 지표 외에 await과 read/write throughput(xx MB/s) 지표와, nand 제품의 성능 한계치(별도의 부하 테스트나 제품 공식 성능 자료 참고)와 비교하며 모니터링에 참고
- iostat 외에 iotop, blktrace, vmstat, perf, flo 등 다양한 툴로 다른 레벨까지 모니터링
%util 계산 방법
io request에 대한 응답 시간을 통해 산출
응답 시간은 tot_ticks을 이용해 계산
io 함수 호출 시마다 디스크가 처리한 응답 시간(tick) 만큼 더하는 방식
io가 시작된 시점과 완료된 시점을 추적하여 계산
a=>b, c=>d 사이의 시간을 카운터에 누적
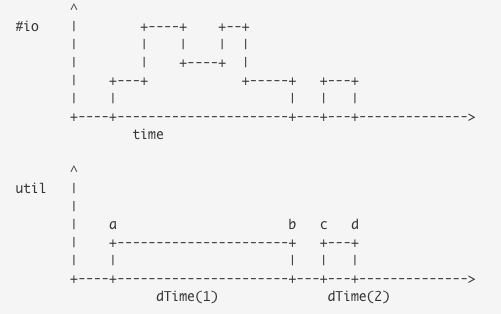
해당 값을 계산하는 코드 → in_flight 인 경우 now - then 값이 추가되는 방식

iostat 설치 방법
$ yum install -y sysstatiostat 명령어 옵션
자주 사용하는 iostat 명령어 옵션
# iostat -dxm 1 -p ALL | grep -iw "device\|sda4\|nvme0n1" | awk '{now=strftime("%Y-%m-%d %T "); print now $0}'참고 $ iostat -dxm 1 -p ALL
자주 사용하는 iostat 명령어 옵션에 대한 설명
- -d : 디스크 사용량 정보를 출력
- -x : 확장 정보 출력
- -m : 초당 throughput 출력 → MB/S으로 출력
- 1 : iostat 출력 간격을 초로 지정 → 1이면 1초마다 갱신
- -p ALL : 시스템에 모든 디바이스를 출력
iostat 출력 값에 대한 설명
1. rrqm/s
- 큐에 대기 중인 초당 읽기 요청 수.
- /proc/diskstats의 결과에서 2번째 줄로 출력
- 장치에 대기 중인 초당 병합된 읽기(read) 요청 수
2. wrqm/s
- 큐에 대기 중인 초당 쓰기 요청 수.
- /proc/diskstats의 결과에서 6번째 줄로 출력
- 장치에 대기 중인 초당 병합된 쓰기(write) 요청 수
3. r/s
- 초당 읽기 섹터 수
- /proc/diskstats의 결과에서 1번째 줄로 출력
- 초당 장치에 발행된 읽기(read) 요청 수
- OS의 block layer가 아니라 Process가 OS의 커널 영역으로 read/write 함수를 호출한 횟수
4. w/s
- 초당 쓰기 섹터 수
- proc/diskstats의 결과에서 5번째 줄로 출력
- 초당 장치에 발행된 쓰기(write) 요청 수
- OS의 block layer가 아니라 Process가 OS의 커널 영역으로 read/write 함수를 호출한 횟수
5. rMB/s
- 초당 읽기 처리 크기 (r/s * 섹터 크기(블록 사이즈 크기))
- proc/diskstats의 결과에서 3번째 줄로 출력
- 초당 장치에서 읽은 메가바이트 수
6. wMB/s
- 초당 쓰기 처리 크기 (w/s * 섹터 크기(블록 사이즈 크기))
- proc/diskstats의 결과에서 7번째 줄로 출력
- 초당 장치에 기록된 메가바이트 수
7. avgrq-sz
- 요청 건수의 평균 크기 ( 1 = 512byte )
- proc/diskstats의 결과에서 출력값 X
- 장치에 발행된 요청의 평균 크기(섹터)
8. avgqu-sz
- 해당 Device에 발생된 request들의 대기 중인 queue의 평균 length
- proc/diskstats의 결과에서 11번째 줄로 출력
- 장치에 발행된 요청의 평균 대기열 길이
avgqu-sz = await / svctm * %util - 상세 설명 : avgqu-sz는 io스케줄러 queue + 디스크 queue의 대기열을 포함된 평균 수치
- io 스케줄러 queue depth 경로 → sys/block/[device]/queue/nr_requests
- 디스크 queue depth 경로 → /sys/devices/pci0000:17/0000:17:00.0/0000:18:00.0/host0/target0:2:0/0:2:0:0/queue_depth
- avgqu-sz 수치보다 await 수치가 훨씬 높으면 디스크 쪽에서 병합이 있다고 판단
9. await
- 레이턴시 값 (svctm + waiting in the queue)
- proc/diskstats의 결과에서 4번째 줄로 출력
- 처리할 장치에 발행된 I/O 요청의 평균 시간(밀리초)
- 대기열의 요청에 소요된 시간과 해당 요청을 처리하는 데 소요된 시간이 포함
await = svctm + however_long_in_quere - 상세 설명 : await는 io 완료 시간 + 스케줄러에서 대기 큐에 소비된 시간을 합친 값
- 해당 값은 스케줄러, 드라이버, 컨트롤러, 실제 물리 디스크 단 까지 모든 대기 시간이 포함
10. svctm
- 장치에 발행된 I/O 요청의 평균 서비스 시간(밀리초)
- proc/diskstats의 결과에서 출력값 X
- svctm의 조기 처리에 대한 조치로 인해 10 io 가 발생하면 10 ms 만에 1 io 는 1 ms 로 처리해 svctm에 1.00 일이 발생
11. %util
- proc/diskstats의 결과에서 10번째 줄로 출력
- 장치에 I/O 요청이 발행된 CPU 시간의 백분율(장치의 대역폭 사용률).
- %util 값이 100%에 가까울 때 장치 포화가 발생
- Disk 가 버틸 수 있는 한계치를 %로 표시해 주는 필드
- 스핀들 디스크에선 잘 처리해서 보여 주지만, 병렬 io처리를 하는 nand제품이나 cache가 달린 Raid 구성 또는 스토리지에서는 신용할 수 없는 정보
iostat 예제 출력 결과로 내용 설명
- iostat 명령어 출력 설명
- 부하 → 4k 블록 사이즈로 read 10MB, write 10MB 부하 확인(read는 r/s, write는 w/s)
- rMB/s 출력 → 4k x 1024(r/s) = 4MB (rMB/s)
- wMB/s 출력 → 4k x 1024(w/s) = 4MB (wMB/s)
- 부하준 블록 사이즈 크기 확인 → 8(avgrq-sz 값) x 512 (byte) = 4kb, 만약 8k 블록 사이즈로 부하를 주면 avgrq-sz는 16으로 표시
- %util 값 → 1025(r/s) + 1025(w/s) / (0.32(svctm) / 10)
- iostat 명령어 출력 결과

iostat 지표는 disk속도나, 문제가 있을 때 확인 → 의미 있는 지표 확인 방법
- 장착된 디스크의 종류 확인 → sata, sas, ssd, nvme 등 물리적 디스크 종류 확인
- raid 구성 확인 →raid는 캐시가 있는, write-back인지. 직접 쓰기하는 write-through인지 확인
- 현재 구성된 디스크의 성능 한계치를 파악
- hdparm 명령어로 하드 디스크 점검 및 성능 측정
- ssd의 경우 read 300MB에 write 80MB 정도
- benchmark를 통해 디스크 성능표도 참고 필요
- rMB/s, wMB/s로 현재 부하 크기를 보고, await 지표가 1 (ms) 이상 넘는지 등을 확인
- SATA나 SAS는 await 값을 유심히 볼 필요 → await 값은 레이턴시 지표로 보면 되고, 디스크 부하는 크지 않은데 await 값이 순간 올라가는 경우가 종종 있음(Nvme, SSD에는 의미 없음)
iostat %util, svctm 지표 오류
- 스핀들 디스크 (SATA, SAS 등)의 경우 플래터가 돌면서 헤더가 지정된 섹터를 찾아 한번에 한 가지 job씩 처리함 → 병렬 처리가 안 되는 구조로, iostst 지표의 값이 정확한 지표라 판단 가능
- Nand (Nvme, ssd)의 경우 die 칩셋이 채널로 구성되며, 각 채널별로 io를 분산 처리됨 → 병렬 처리가 가능(병렬 처리하여 퍼포먼스를 높이더라도 iostat 툴에서는 계산하지 못함)
- SSD 병령 처리 구성

- Nand 제품에선 적은 부하를 줘도 %util 에선 과도하게 높은 지표를 출력 가능
- nvme 디스크에 (fio 테스트, 4k 블록 사이즈, radomwrite 부하) numjob을 늘려가며 테스트 결과를 확인하면, job=3부터 이미 %util 은 최대치를 도달
- 이론상 %util이 100이 되면 디스크 포화 상태를 의미하지만 부하를 더 줄수록 write 성능 증가 → 즉, %util 필드 자체는 의미 X

'OS(운영체제) > 리눅스 명령어' 카테고리의 다른 글
| grep 명령어에서 AND, OR, NOT 조건 사용하기 (0) | 2022.07.03 |
|---|---|
| mount 명령어 (하드웨어 장치를 사용하기 위해 디렉토리에 연결) (0) | 2022.07.03 |
| hdparm 명령어(하드 디스크 점검, 하드 디스크 성능 측정) (0) | 2022.06.26 |
| 현재 서버의 IP 확인 명령어 종류들 (정리 중) (0) | 2022.06.26 |
| vmstat 명령어 (메모리 상태 확인하는 명령어) (0) | 2022.06.26 |