C/G/S/P states
- intel_idle과 관련된 내용을 다루기에 앞서 P-States와 C-States에 대해서 간단히 정리
- Intel 아키텍처 환경에서 리눅스 커널과 CPU를 알아가다보면 P/S/G/C States에 대한 학습 필요
1. P-States
- P-States는 작업 부하에 따라서 CPU의 전압과 클럭주파수를 조절하는 정도를 정의 한 값
- 명령어 처리(Operation)상태를 기준으로 절전 및 성능 향상을 꾀하기 위한 기법
- 과거에는 SpeedStep이라는 기술로 소개 되었지만 정확히 같은 것은 아님
- P-States는 단순히 클럭주파수를 조절해서 에너지 절약을 위한 방안으로만 치부되었는데 CPU가 연산처리를 할 때의 상태를 반영
- 최근 사용되는 Intel CPU의 Turbo Boost 상태는 P-State 0(P0)를 의미
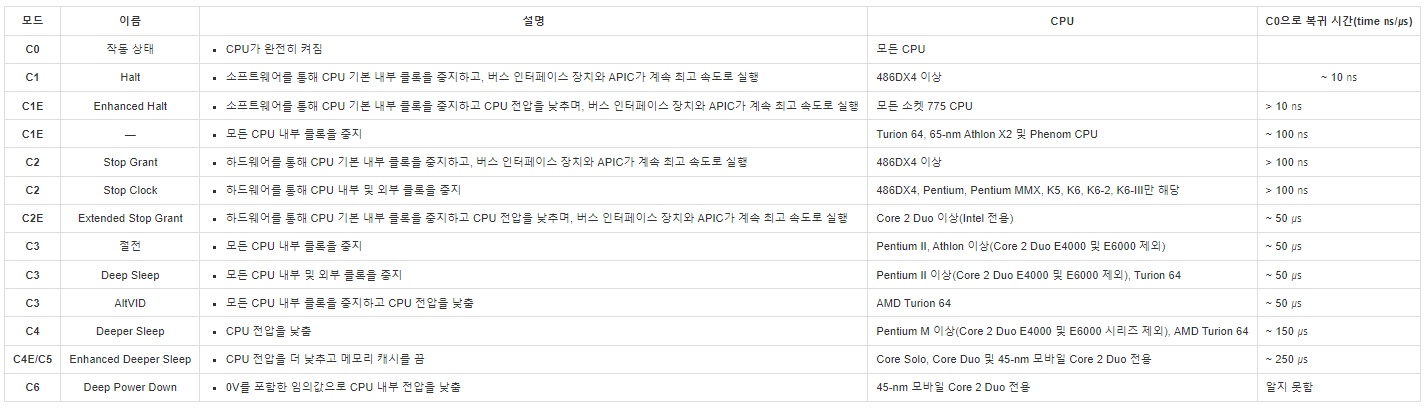
2. C-States
- C-States는 CPU 내부의 특정 부분이 활성화되거나 낮은 성능 상태로 실행될지를 반영하는 값
- CPU에서 사용중이 아닌 부분들을 비활성화하여 전원의 효율화를 높이기 위한 상태 값
- P-State와 다르게 C-State는 유휴(Idle)상태를 기준으로하여 평가
- C0는 활성화된 일반적인 상태를 의미하며, C0 상태에서 P0~Pn 상태로 나누어서 볼 수 있음
- Nehalem Microarchitecture(네할램)부터는 C6 상태가 추가되었는데 C6는 각종 작업들을 저장하고 이미 작동을 멈춘 CPU 코어에 공급되는 전원을 차단하는 상태
- Sandy Bridge Microarchitecture(샌디브리지)에서 C7이 추가되었고 이는 C6에서 추가로 L3캐시까지 비워버린(Flush) 상태를 의미
3. G-States
- Global States를 의미
- 사용자가 인지할 수 있는 상태를 반영
- G0는 동작상태 (전원 On)
- G1은 잠자기모드 상태
- G3는 전원 Off 상태
4. S-States
- Sleep States를 의미
- G1에서 세부적인 잠자기모드 상태를 나타냄
5. Processor Power States → 상태들을 알아보기 쉽게 도식화

intel_idle → Idle 상태를 관리
- C-States와 관련이 있는 모듈
- intel_idle이 사용되기 이전에는 C-States를 OS에서 관리하기 위해서 acpi_idle이란 모듈이 사용
- 기존 acpi_idle 모듈의 경우 C-State latency와 관련하여 정확도도 높지 않았고 기본적으로 BIOS 설정에 따라서 주어진 환경 내에서만 상태를 변경하는 정도로 효과 X
- intel_idle의 경우 BIOS 설정에 직접적으로 개입하여 C-State를 조절하는 모듈
- 서버시스템의 경우 빠른 응답속도를 목표로하기 때문에 소위 Performance 모드로 통칭되는 BIOS 설정상태를 유지하여 CPU가 잠들지 않도록 하는 설정하였지만, C-State를 커널이 개입하여 CPU 상태를 제어해 버리면 성능에 문제가 있을 수 있음
- 하드웨어에서 Performance이지만 커널에서 C6으로 C-State가 설정되어있으면 C6 상태에 있던 CPU가 C0 상태로 만들기 위한 시간(Wake-up time)이 소모되어 성능 저하 발생
- intel_idle 모듈 설정을 통해 BIOS 설정과 무관하게 커널의 C-State를 조절 필요
Idel 상태 관리 방법
- intel_idle.max_cstate 파라미터를 통해 C-State의 상태를 결정하거나 비활성화하여 apci_idle 사용가능
- 커널 부팅 파라미터에 intel_idle.max_cstate=0 값을 설정하면 apci_idle을 사용하여 하드웨어의 C-State로 부팅
- 커널파라미터의 경우 rebooting의 부담이 있기 때문에 기존에 운영하는 장비도 적용 할 수 있도록 tuned의 profile을 이용한 설정
1.커널 매개 변수로 intel_idle.max_cstate=0을 적용
grub 파일을 쓰고 있다면, /etc/default/grub 파일에 intel_idle.max_cstate=0를 설정한 후 설정 적용(재부팅 가능)
GRUB_CMDLINE_LINUX="crashkernel=auto spectre_v2=retpoline rhgb quiet" 항목에 intel_idle.max_cstate=0 추가
# /etc/default/grub 파일 수정 $ vi /etc/default/grub GRUB_TIMEOUT=5 GRUB_DISTRIBUTOR="$(sed 's, release .*$,,g' /etc/system-release)" GRUB_DEFAULT=saved GRUB_DISABLE_SUBMENU=true GRUB_TERMINAL_OUTPUT="console" # 변경 전 내용 : GRUB_CMDLINE_LINUX="crashkernel=auto spectre_v2=retpoline rhgb quiet" # 아래 변경 후 내용 GRUB_CMDLINE_LINUX="crashkernel=auto spectre_v2=retpoline rhgb quiet intel_idle.max_cstate=0" GRUB_DISABLE_RECOVERY="true" # /etc/default/grub 파일 적용 $ grub2-mkconfig -o /boot/grub2/grub.cfg $ reboot
※ 참고
- 재부팅 후 intel_idle이 정상적으로 적용되었는지 확인 필요
$ dmesg | grep -i intel_idle
2. tuned의 profile의 latency-performance의 profile을 이용한 설정
- tuned의 profile 중 latency-performance의 profile을 통해 커널파라미터의 경우 리부팅의 부담을 줄이고 C-state 변경 작업 적용
- 아래 결과를 통해 C7 상태까지 떨어지던 idle 상태가 C1이하로 내려가지 않는 것 확인
$ tuned-adm profile latency-performance
- latency-performance 적용 전

- latency-performance 적용 후
3. E3/E5 계열(샌디브리지)의 CPU는 바로 적용이 되었으나 C6까지있는 네할렘 CPU에는 바로 적용 불가
- 실제 장비들을 샘플링하여 테스트 해 본 결과 tuned-adm을 설정하더라도 E3/E5 계열(샌디브리지)의 CPU는 바로 적용이 되었으나 C6까지있는 네할렘 CPU들은 적용 불가
- 네할렘 CPU에 C6은 계속 출력되는 것 확인
- /dev/cpu_dma_latency 장치(4바이트 값을 갖는 장치)에 직접 latency 값을 100으로 설정
$ exec 3> /dev/cpu_dma_latency $ echo -ne '\0144\000\000\000' >&3
- 네할렘 CPU에 C3까지 출력되는 것 확인 → /dev/cpu_dma_latency 변경 확인
※ 아래 참조한 자료는 RHEL6 버전으로 RHEL7을 확인 필요
- 참조 URL : https://lunatine.net/2015/01/06/rhel6-intel_idle-and-c-states/
- 리눅스 ( Tuned 데몬을 이용한 OS 튜닝) 튜닝 참고 URL : http://justinsona.blogspot.com/2016/11/tuned-os.html
'OS(운영체제) > 리눅스(Linux)' 카테고리의 다른 글
| 작업 예약 스케줄러(cron) 파일 (0) | 2022.07.23 |
|---|---|
| SFTP (SSH 또는 Secure File Transfer Protocol) (0) | 2022.07.23 |
| P-State (Performance-state) → CPU를 사용하는 active 상태 (0) | 2022.07.21 |
| C-State → CPU 사용량이 적은 idle 상태 (0) | 2022.07.21 |
| Linux 접속 로그 → btmp, wtmp, utmp, lastlog (0) | 2022.07.18 |