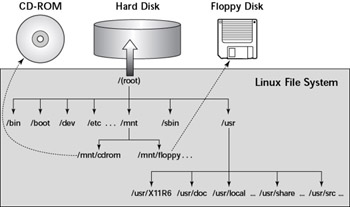
- hdparm 명령어는 시스템에 장착된 하드디스크의 속도와 성능을 테스트할 수 있음 → 실무에서 IDE 또는 SCSI 하드디스크의 ACCESS 속도를 측정할 때에 많이 사용
- hdparm 명령어로 하드디스크의 직접적인 성능에 영향을 줄 수 있는 여러가지 설정이 가능하지만, 극히 위험한 상황을 초래할 수 있으므로 설정의 용도로는 사용하지 않는 것이 좋음
- hdparm 명령어로 점검하는 하드디스크의 속도는 절대적인 것이 아님 → 동일한 시스템에서 동일한 환경으로 테스트한 결과값도 조금 다르게 나올 수 있음
- CPU와 메모리, 그리고 시스템 사양에 따라서 hdparm 테스트 결과가 매우 다르게 나올 수 있음 → 대략적인 하드디스크의 읽는 속도를 확인하기 위하여 hdparm 명령어은 매우 유용
hdparm 명령어 설치
$ yum install -y hdparm
명령어위치
$ which hdparm
/sbin/hdparm
하드디스크를 구입 기준
- IDE하드디스크인가? 아니면 SCSI하드디스크인가?
- 하드디스크의 RPM(디스크의 분당 회전수)은 얼마인가?
- 하드디스크의 용량은 얼마인가?
- 어느회사에서 생산한 제품인가?
- 하드디스크의 안정성은 확보되어있는가?
- 하드디스크의 외관
hdparm 명령어 옵션
hdparm 명령어 주로 사용하는 옵션
- -t : 버퍼되어 있지 않은 데이터를 읽는 속도 체크
- -T : 버퍼된 데이터를 읽는 속도를 체크
hdparm 명령어로 버퍼링되지 않은 데이터의 디스크 ACCESS 속도 체크하기
- 시스템에 장착되어 있는 SCSI하드디스크의 속도를 체크
- -t 옵션을 사용한 것은 버퍼링(buffering)이 전혀 되어있지 않은 데이터를 실제로 디스크에서 얼마나 빠르게 읽을 수 있는가를 확인
- hdparm명령어는 실제로 2~3회의 테스트를 실시한 후에 출력
- SCSI 하드디스크가 IDE 하드디스크보다는 데이터의 읽은 속도에 있어서 현저하게 성능이 높음
1.SCSI 하드디스크 테스트 결과
2.IDE 하드디스크 테스트 결과
hdparm 명령어로 버퍼링 유무 데이터 ACCESS 속도 비교하기
- 캐쉬(cache)에 버퍼링되어 있는 데이터를 읽는다면 실제 속도는 엄청나게 빨라짐
- 캐쉬(cache)에 저장된 데이터를 읽는다는 것은 실제로 디스크에서 읽어오는 것이 아니라 캐쉬메모리(cache)에서 읽어오는 것이기 때문임
- 위에서 설명한 -t 옵션은 디스크에 존재하는 데이터를 읽는 속도를 테스트하는 것이라면, -T 옵션은 캐쉬에 존재하는 데이터를 읽는 속도를 테스트
1. SCSI 디스크의 캐쉬에 버퍼링되어 있는 데이터와 실제 디스크에서 데이터의 읽는 속도 비교
- 캐쉬메모리가 시스템의 속도에 막대한 영향을 미침을 확인 가능
- 캐쉬에 버퍼링되어 있는 데이터(T옵션)를 읽을 때에는 초당 약 220MB
- 실제로 디스크에서 데이터(t옵션)를 읽어오는 속도는 초당 약 65MB
$ hdparm -tT /dev/sda
/dev/sda:
Timing buffer-cache reads: 128 MB in 0.58 seconds =220.69 MB/sec
Timing buffered disk reads: 64 MB in 0.97 seconds = 65.98 MB/sec
2. IDE 디스크의 캐쉬에 버퍼링되어 있는 데이터와 실제 디스크의 읽는 속도 비교
- 캐쉬메모리가 시스템의 속도에 막대한 영향을 미침을 확인 가능
- 캐쉬에 버퍼링되어 있는 데이터(T옵션)를 읽을 때에는 초당 약 216MB
- 실제로 디스크에서 데이터(t옵션)를 읽어오는 속도는 초당 약 25MB
$ hdparm -tT /dev/hda
/dev/hda:
Timing buffer-cache reads: 128 MB in 0.59 seconds =216.95 MB/sec
Timing buffered disk reads: 64 MB in 2.48 seconds = 25.81 MB/sec
SSD가 Trim 기능 지원여부 확인 → Trim 사용하면 /etc/fstab에 discard를 추가
1. hdparm 명령어에 -I 옵션을 통해 SSD의 Trim 기능 확인
$ hdparm -I /dev/sda
/dev/sda:
ATA device, with non-removable media
Model Number: DELLBOSS VD
Serial Number: 00321258d60c0010
Firmware Revision: MV.R00-0
Standards:
Used: ATA/ATAPI-7 T13 1532D revision 4a
Supported: 8 7 6 5 & some of 8
Configuration:
Logical max current
cylinders 16383 16383
heads 16 16
sectors/track 63 3
--
CHS current addressable sectors: 7864440
LBA user addressable sectors: 268435455
LBA48 user addressable sectors: 468731008
Logical Sector size: 512 bytes
Physical Sector size: 4096 bytes
device size with M = 1024*1024: 228872 MBytes
device size with M = 1000*1000: 239990 MBytes (239 GB)
cache/buffer size = 8192 KBytes (type=DualPortCache)
Capabilities:
LBA, IORDY(cannot be disabled)
Queue depth: 32
Standby timer values: spec'd by Standard, no device specific minimum
R/W multiple sector transfer: Max = 16 Current = ?
Recommended acoustic management value: 254, current value: 0
DMA: mdma0 mdma1 mdma2 udma0 udma1 udma2 udma3 udma4 udma5 udma6 *udma7
Cycle time: min=120ns recommended=120ns
PIO: pio0 pio1 pio2 pio3 pio4
Cycle time: no flow control=120ns
Commands/features:
Enabled Supported:
* Power Management feature set
* Write cache
* Look-ahead
* DOWNLOAD_MICROCODE
* 48-bit Address feature set
* Mandatory FLUSH_CACHE
* FLUSH_CACHE_EXT
* Gen1 signaling speed (1.5Gb/s)
* Gen2 signaling speed (3.0Gb/s)
* Gen3 signaling speed (6.0Gb/s)
* Native Command Queueing (NCQ)
* Data Set Management TRIM supported (limit 1 block) # 해당 부분 TRIM 표시
Security:
Master password revision code = 65534
88min for SECURITY ERASE UNIT. 88min for ENHANCED SECURITY ERASE UNIT.
Checksum: correct
2. lsblk -D가 0이 아니면 TRIM 사용 가능
$ lsblk -D
NAME DISC-ALN DISC-GRAN DISC-MAX DISC-ZERO
sda 0 4K 2G 0
├─sda1 0 4K 2G 0
├─sda2 0 4K 2G 0
├─sda3 0 4K 2G 0
└─sda4 0 4K 2G 0
sdb 0 0B 0B 0
└─sdb1 0 0B 0B 0
sdc 0 0B 0B 0
└─sdc1 0 0B 0B 0
sdd 0 0B 0B 0
└─sdd1 0 0B 0B 0
sde 0 0B 0B 0
└─sde1 0 0B 0B 0
sdf 0 0B 0B 0
└─sdf1 0 0B 0B 0
sdg 0 0B 0B 0
└─sdg1 0 0B 0B 0
sdh 0 0B 0B 0
└─sdh1 0 0B 0B 0
sdi 0 0B 0B 0
└─sdi1 0 0B 0B 0
sdj 0 0B 0B 0
└─sdj1 0 0B 0B 0
sdk 0 0B 0B 0
└─sdk1 0 0B 0B 0
3. TRIM 최대 사용 bytes 확인 -> TRIM을 사용할 수 없으면 0으로 출력
$ cat /sys/block/sda/queue/discard_max_bytes
2147450880
4. TRIM 지원 Bock size 확인 -> TRIM을 사용할 수 없으면 0으로 출력
$ cat /sys/block/sda/queue/discard_granularity
4096